Distilling the web for multi-agent automation.
Introduction
Our everyday interactions with computers are filled with slow and repetitive tasks. Often, even if you know exactly what you’d like to accomplish on your device, it takes a certain amount of tedious labor (physical use of the mouse and keyboard) to reach your destination.
Automating these workflows would result in significant time savings and reduced cognitive load for humans. The advent of large language models (LLMs) and large vision models (LVMs) opens the door to creating systems that can take natural language instructions to perform intelligent functions, including actions in the physical and digital world.
Agents driven by LLMs and LVMs can, under the right circumstances, follow instructions in a collaborative manner. This allows for computing systems to more seamlessly mesh with human systems, leading to a spectrum of new collaborative paradigms, ranging from blended human/computer teams to fully autonomous goal-oriented computer systems.
Emergence believes that an unprecedented amount of web automation can be achieved by using a general-purpose LLM and a properly compacted HTML DOM. This belief drove us to the creation you can read about below.
Agent-E
Emergence is proud to present our first web-interaction agent. This agent, which we’ve dubbed “Agent-E,” can control and complete tasks on a webpage based on natural language instruction. Through our testing, our agent has shown competence in things like e-commerce shopping, searching the web, and selecting for vetted content from specific websites. It’s also adept at form-filling (say, “Enter my information into this form my doctor sent me”), question-answering (“How much does X cost?”), and text-extraction (“What’s today’s top soccer news?”).
Soon, Emergence will release the code for this agent in the open source community, so anyone interested may use it to build agents that make people’s lives easier. We will provide the link to its GitHub repository, along with some demo videos, in upcoming announcements.
Our web agent architecture is built on the framework known as Agent-Oriented Programming (AOP), in which each agent in a system, at the minimum, adheres to four basic characteristics:
- Sensing: It can sense its environment.
- Processing: It processes the sensed signal from the environment using an intelligence engine driven by LLMs, LVMs, long-term memory modules, etc.
- Action: It can affect its external environment through tools or code.
- Self-improvement: It improves itself continuously at a given task as dictated by its constitution.
For more details on the agent object model please refer to our previous blogs.
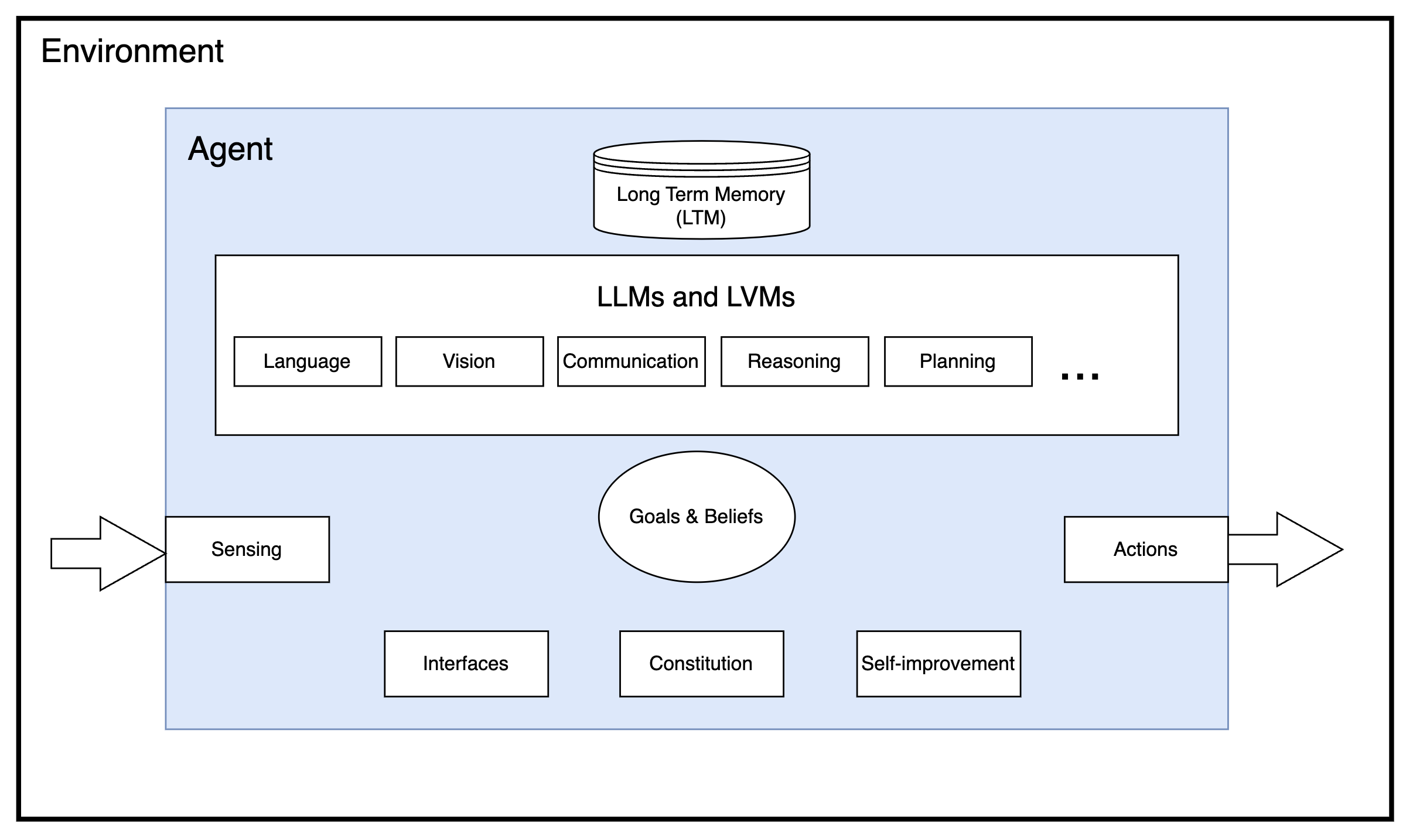
(Definition of an Agent).
Description
Our agent builds on a scalable array of atomic actions, which we call “skills.” The agent learns to use its skills as building blocks toward completing a large, complex workflow, as opposed to trying to learn the entire workflow as one construct. This affords our agent the ability to scale to other tasks, as the learned atomic actions which allow manipulation of a web page are reusable from one task to another.
What does changes between disparate tasks is the means by which these atomic actions are stitched together. Our agent’s intelligence layer, driven by an LLM, learns how to stitch these atomic actions together and in what order for each task at hand.
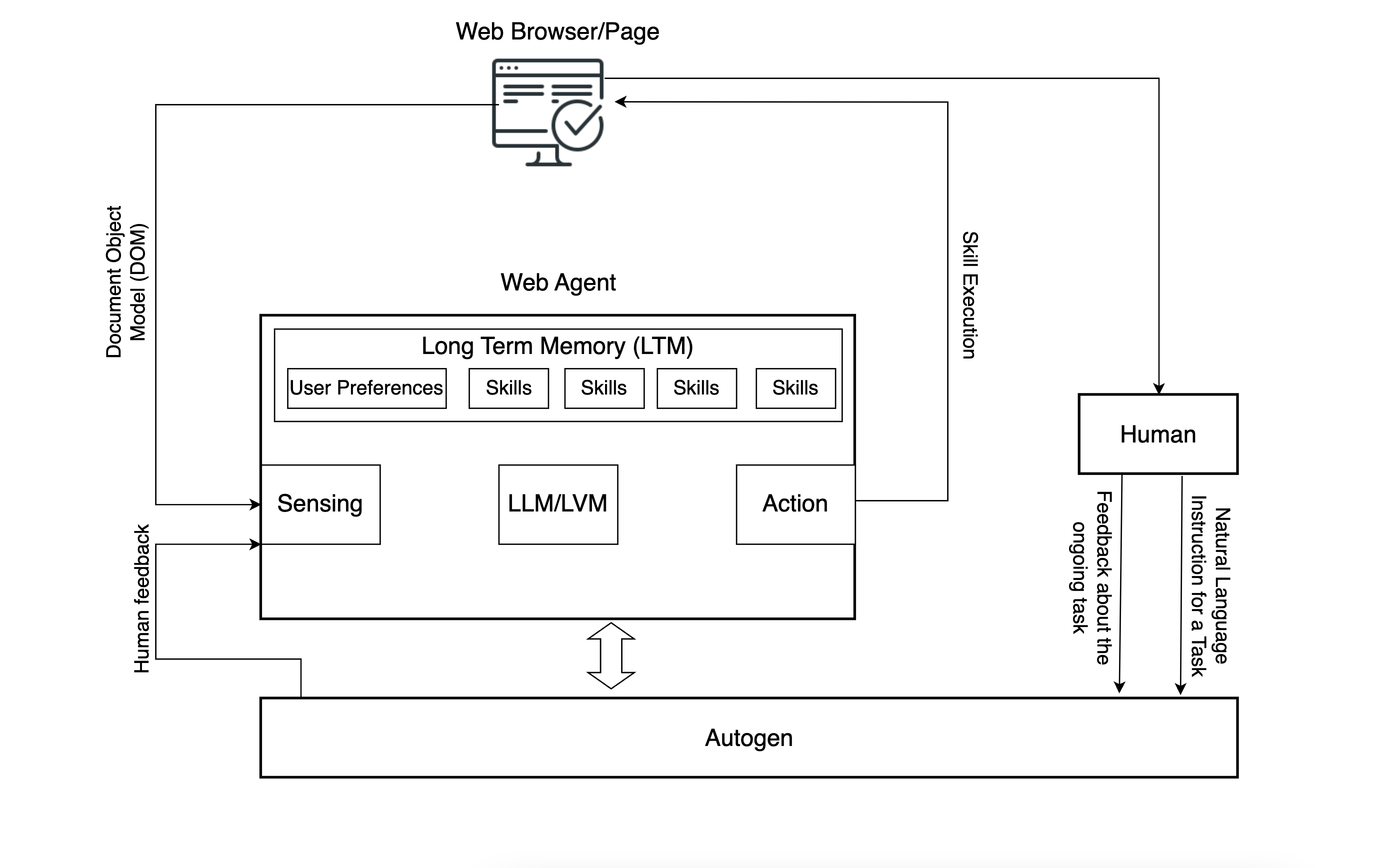
(Architecture of Agent-E interacting with human inputs and webpage execution).
Skills/Atomic Actions:
To select which skills to implement off the bat, we simply looked at how humans use the web. Together, these skills can perform a task and then return natural language text explaining the output.
Each skill, whether it failed or succeeded in a given moment, responded afterwards with natural language that indicated that success or failure along with potential reason(s). Making the skills’ outputs more conversational yielded better results than returning a boolean true/false (indicating success/failure). The natural language response helped the LLM figure out how to course correct when errors occurred.
Skills fall into two categories:
- Sensing skills: These help the agent understand the state of the webpage or the browser.
- Action skills: These allow the agent to act on a webpage or a browser.
| Sensing Skills | Action Skills |
| geturl - Fetches and returns the current url. | click - given a DOM query selector, this will click on it. |
| get_dom_with_content_type - Retrieves the HTML DOM of the active page based on the specified content type. Content type can be:‘text_only’: Extracts the inner text of the html DOM. Responds with text output.‘input_fields’: Extracts the interactive elements in the DOM (button, input, textarea, etc.) and responds with a compact JSON object.‘all_fields’: Extracts all the fields in the DOM and responds with a compact JSON object.get_user_input - Provides the orchestrator with a mechanism to receive user feedback to disambiguate or seek clarity on fulfilling their request. | enter_text_and_click - Optimized method that combines enter text and click skills. The optimization here helps use cases such as enter text in a field and press the search button. Since the DOM would not have changed or changes should be immaterial to this action, identifying both selectors for an input field and an actionable button can happen based on the same DOM examination. |
| bulk_enter_text - Optimized method that wraps enter_text method so that multiple text entries can be performed one shot. | |
| enter_text - Enters text in a field specified by the provided DOM query selector. | |
| openurl - Opens the given URL in current or new tab. |
DOM Distillation:
The size of the DOM can also have implications on the speed of processing, cost, and the quality of reasoning by the LLM. Hence DOM compaction/distillation is an important step of pre-processing to improve important language signals in the DOM before an LLM can process it.
HTML DOMs can be so large that, often, they do not fit in an LLM’s context window and are therefore unusable by the LLM.
The image below shows the number of tokens required to represent the raw HTML of popular websites, compared with the tokens needed after our distillation process.
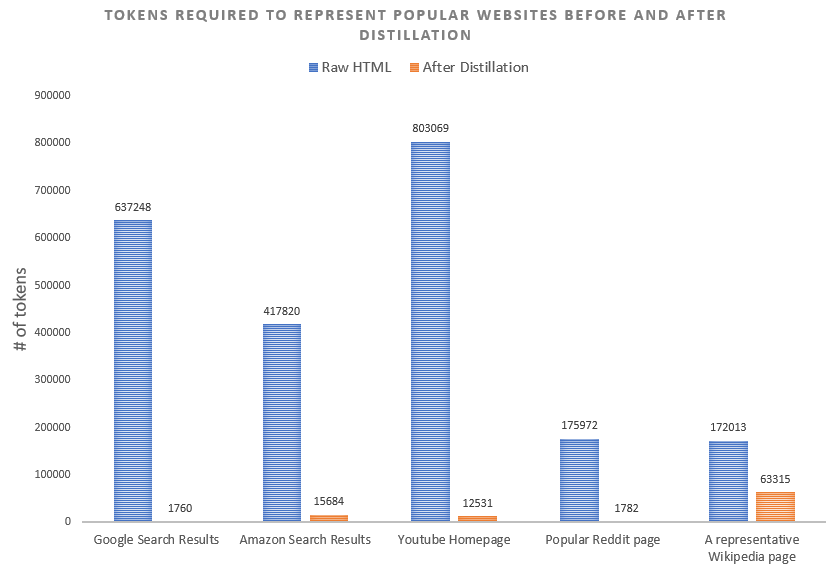
We train the agent to approach the DOM in a way that is modeled after a human approaching a website.
Only a small portion of the information in the DOM is relevant to any given task performed by an agent. Humans effortlessly extract relevant information from a webpage when performing a task. This ability to intuitively filter task-irrelevant content improves as the user gets more familiar with the webpage. For example, if a user is on an e-commerce site looking for lightning deals, the product search engine functionality might not be the thing a user is most interested in. Therefore, they visually “block” it, using the selective attention phenomenon called “banner blindness.”
Given a task, the LLM is able to decide what specific DOM content it needs, “distilling” the DOM down to only the necessary elements. This distilled DOM is a hierarchical JSON document (except in the rare case of a text-only webpage) that can be sent to an LLM for predicate resolution, where a predicate is a step in the execution plan, such as identifying the text search field on this page.
{
"tag": "button",
"aria-label": "Skip navigation",
"mmid": "898",
"description": "Skip navigation
},
{
"role": "combobox",
"name": "search\_query",
"autocomplete": "list",
"haspopup": "listbox",
"value": "cat videos",
"tag": "input",
"tag\_type": "text",
"placeholder": "Search",
"mmid": "919"
}
(Sample DOM representation from YouTube).
Planning & Reasoning
When the agent receives an utterance such as “Find Nothing Phone 2 on Amazon and sort the results by best seller,” its LLM prepares a plan of action. If some information is missing, the LLM can reason out that it needs more information from the user before moving forward with the plan. Then, before it can begin taking action, the agent actively decides what kind of sensing skills must be deployed to accurately prepare a plan of action.
Sometimes, ambiguities (say, there are multiple variants of Nothing Phone 2 with various specifications) and unexpected challenges (say, a missing or broken search box on this page) may arise during execution. The LLM can adapt the plan based on this new information, or it can prompt the user for further clarification, such as, “Would you like me to sort the phones based on user rating or price?”
Extensible Architecture
Our web agent architecture is highly scalable and extensible. More skills can be added very easily by registering new skills using the Autogen framework [2]. It then creates a JSON representation of the skills to make use of LLMs that support function calling. The verbose representation of skills, while advantageous, can consume a significant number of tokens. We are considering using a lightweight router that can provide a compact representation of the available skills to the LLM while exposing itself as a skill so that it maintains the skill registration and extension paradigm.
How to precisely represent the state of the world, in this case state of the DOM, is an area of active exploration. The smaller the DOM slice shared with the LLM, the faster and cheaper the response will be. This might be achievable by adding other content types or better distillation techniques. A compact representation of the state will allow for smaller LLMs that are hosted locally to perform these tasks which could boost privacy and adoption.
Evaluation
Our evaluation of the agent is inspired by WebArena [1]. Web Arena, however, performs its evaluation against static, curated, and self-hosted sites. We are using the “wild web” and approximating our evaluation. We are looking at ways to use a modified version of Web Arena to objectively evaluate our web agent.
Conclusion
In conclusion, Agent-E is built on the following key contributions:
-
Intelligent DOM distillation where only the relevant parts of the DOM are retained based on the plan of action for the completion of the task. This ensures that only the relevant information about the webpage goes into the LLM context window for further processing.
-
A scalable skills registry architecture where atomic actions or sensing mechanisms can be easily plugged in with their capability manifest, and the agent automatically starts using that capability in the next set of task executions.
We believe that highly capable web agents may be the path to extensive automation. They could perhaps lead to the creation of general task-performing intelligence capabilities, seeing as a big part of our digital world is web-based. We also believe, however, that these generally capable web agents will co-exist with agents that are highly specialized toward some mission-critical complex task that requires extreme accuracy. This presents a huge opportunity for enterprise workflow automation, where the tools are increasingly web-based and workflows are task-specific, which lends itself to using a configurable agent architecture for automation.
Our code is now live and open-source on GitHub, where we invite you to collaborate with us and where we have an ambitious list of to-dos.
References
[1] Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, Graham Neubig (2023). Webarena: A realistic web environment for building autonomous agents. arXiv preprint arXiv:2307.13854.
[2] Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W White, Doug Burger, Chi Wang (2023). AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation arXiv preprint arXiv:2308.08155